# 深入理解资源平衡与二次调度机制
作者平时也得工作和干活~,尽量在有空的时候不断的去更新该博客...
如果有相关问题或反馈,可以加作者微信(微信号:SPE3SRU3STAY)
本文默认:
您已经了解以下组件的“基本概念”和“常规用法”:
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- kube-proxy
- kubectl
- kubelet
- etcd
# 要解决的问题
# 与朋友闲聊时提起的内容:
互联网业务都会一个明显的波峰波谷,To C业务的波峰波谷会更加剧烈,波峰波谷可能会有两个数量级的一个差异。
当研发在波谷的时候进行一次发布,这时候就会触发容器的一次重新调度,比如像我这个服务有几十个 Pod 的,可能会有十多个 pod 调度到一台机器,因为这时候的机器的使用率很低,就是服务怎么调度其实都可以。
但是到了晚高峰的时候,我的每一个 pod 资源的使用率就上来的,CPU 使用高了,它的吞吐也高了,然后我这十个Pod都在同一个机器上,我这台机器就会出现一些资源的瓶颈。
# 从中抽象出的问题:
Node节点资源调度不均匀,
波峰与波谷之间的访问量诧异巨大,导致各节点资源利用不均衡,高负载Pod扎堆聚集在几个特定的Node之上,从而触发资源瓶颈和某些运维成本的增加。
以上的这个问题该如何去解决?
# 原理探索
解决思路:
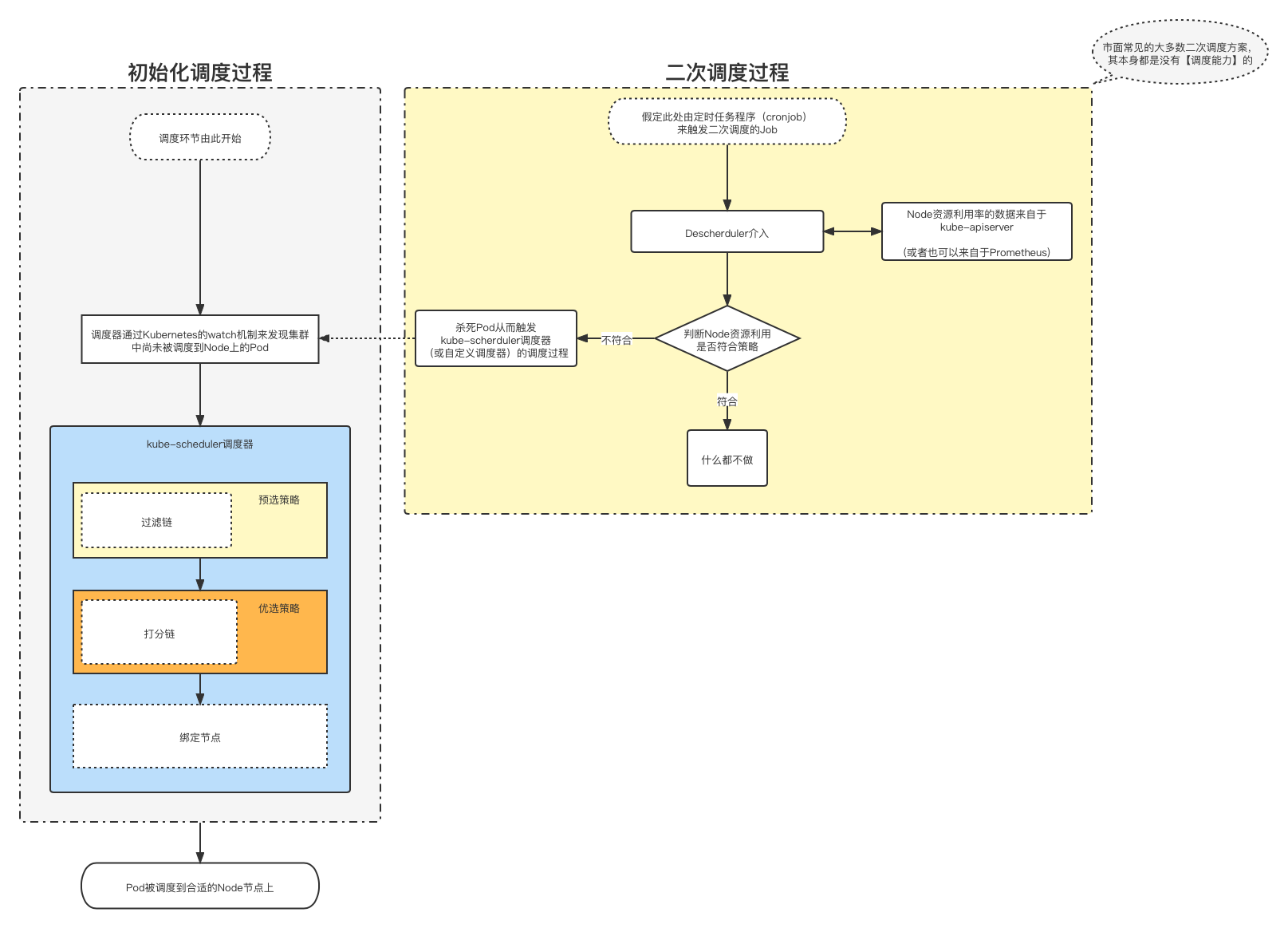
kube-schduler调度器只能完成对Pod的
一次调度。当Pod被调度到指定节点上之后,kube-scheduler就无法再次调度这个运行中的Pod。而我们想要的是
全时段的对Pod的某种动态调度,以求来达到Node资源平衡利用的最终预期。(比如每10分钟重新调度一次,一天差不多调度144次)那是不是我们可以手动的去
杀死某些Pod,来让这些Pod回归到kube-scheduler监听的未调度Pod清单中,触发kube-scheduler的二次调度。同时手动
杀死的Pod时,我们是不是应该还得引入某种条件和策略;不能随意乱杀,要是能按照某种策略或者条件的去杀死指定的Pod,那么解决方案会不会更优美。接着利用
(Deployment或StatefulSets总是会维持一个期望数量Pod的特性)拉起新的Pod,自然而然的让新Pod重走一遍kube-scheduler的过滤链和打分链,以便为新Pod重新寻找到一个资源富裕的Node节点,最终把Pod调度分配过去。最后一步,我们是不是可以把上面每一次
杀死Pod的过程,设定为某种自动化,让它每10分钟去执行一次,完全解放我们的双手。
调度器通过Kubernetes通过list-watch机制来发现集群中尚未被调度Node上的Pod,感兴趣的同学可以自行查阅相关概念。
基于以上的解决方案,我们可以得出来一些清晰的理论支撑:
理论支撑:
仅仅依赖kube-scheduler调度器无法
全时段的动态调整Node资源利用率。我们必须引入
某种二次调度的概念来实现对Pod资源的再调度,以求达成全时段内资源的动态调度与平衡。如果kube-scheduler自带调度策略不够用,我们可以开发
自定义调度器来实现更加精细化的调度需求。
自定义调度器分为四大类:
分类一:
直接clone官方的kube-scheduler来修改源码(不推荐)
分类二:
单独开发一个调度程序,使其和kube-scheduler同时运行,可以指定Pod的spec.schedulerName属性,来让当前Pod选择遵从哪个调度器的调度指令。
分类三:
使用Scheduler extender(调度程序扩展器),利用webhook去和上游调度程序兼容。(kubernetes-1.16版本之后已经废弃)
分类四:
通过调度框架(Scheduler Framework)在整个调度链路中追加扩展点,我个地方我自己的理解是:有点类似于Vue.js页面加载过程中的那种生命周期一样,我们可以利用Scheduler Framework框架,来对生命周期中指定的环节进行再加工。(kubernetes-1.15之后引入,同时也废弃了上文中的"调度程序扩展器"的用法)
# 最终方案
波峰波谷之间的变化是随着
时间线来变化的,因此不论是【kube-scheduler的调度策略】还是【自己开发的调度器】,本质上都无法做到动态调整,所以引入【二次调度】的机制就尤为重要。通过定时性的运行【二次调度】程序,去“杀死”那些Node节点上超过阈值的资源占用,然后利用kube-scheduler的重新调度,彻底实现Node资源的再平衡。
在技术选型时,我们这里选择
DeScheduler工具来实现以上问题的解决。
# DeSchduler使用教程
略...
(网上一搜一大堆)
# 自定义调度器 · 从哪里开始?
有很多公司会去考虑开发自定义调度器来解决某些精细化调度的问题,那么我们应该从哪里开始入手进行开发呢?从上文中可以看出,整个调度、二次调度的闭环中,有两个环节都可以适当的插入一些自己开发的东西:
自定义开发的思考:
环节一:
从Scheduler Framework(调度框架)这个位置进行的开发:
- 可以扩展kube-scheduler的能力(固然这一部分运维成本会增加一些,但是长期来看是非常利好的,可以从粗放型调度向精细化型调度转变)。
环节二:
从Descheduler(二次调度)这个位置进行的开发:
从这个位置做开发,有一个误区:
就是建议不要去跟kube-scheduler抢夺调度能力我们可以自己开发一个【二次调度工具】,去判断当前哪些Node的利用率过高,或者集成上
Pod的亲和性调度再或者兼容污点容忍度等等某些特性,去当做“杀死”Pod的某种阈值和依据;甚至不相信kube-apiserver中查询到的Node资源利用率,而是自己对接Prometheus数据源实时抓取Node真实监控利用率来当做判断依据都是可以的。把自己的开发产物定位在
仅仅只是判断Node的资源利用状态,可以对接QoS机制杀死指定Pod的工具这个角色位置上。实际的调度还是由kube-scheduler去做,这样的综合运维成本会被压低很多。因为如果我们人为开发
自定义调度器去抢夺kube-scheduler的调度能力的话,就必然要实现一条【过滤链】和【打分链】,这种开发、后期维护、版本兼容性、等等问题的持续性伤害,可能会让运维综合成本变得很痛苦。
上面这个问题涉及到综合运维成本,可能作者的想法也不太正确,视角有所缺失等等,算作是抛砖引玉,期待着和大家一起交流和探讨,更欢迎大佬多多批评和指正~。
(全文到此结束)
# 帮助作者改进文档
如果您喜欢这篇文档,想让它变得更好,您可以:
- 推荐这篇文档,让更多的人知道。
- 给作者反馈和建议:tianye3223@gmail.com